
Урок: оцифровка текста.
Оптическое распознавание символов (OСR) используется для превращения изображений текста в текстовые данные на компьютере. То есть, с помощью OСR символы текста на изображениях преобразуются в цифровые данные пригодные для записи на электронные носители.
Изображения страниц печатных документов обычно получают сканерами изображений. Подробнее о сканерах читаем тему: оцифровка документов.
Широкое распространение технология OСR приобрела при оцифровке книг и документов. Лучший софт для OСR - ABBYY FineReader. Программа переводит изображения страниц документов (фотографии, сканы, PDF-файлы) в электронные редактируемые форматы. Как распознает текст FineReader и как работать в этой программе рассказывается в уроке распознаем текст FineReader'ом.
Для распознания текста имеется немало и онлайн-ресурсов. Например: img2txt.com или newocr.com.
Одним из простейших способов извлечения текста из картинок является популярный сервис Google Картинки.
Предположим, нам нужно оперативно решить следующую прикладную задачу. Внести изменения в имеющийся печатный документ. А электронной версии документа нет. Не стоит набирать текст с клавиатуры, когда у нас под рукой сканер. Сканируем страницы документа и сохраняем их в формате JPG. Так я отсканировал четырехстраничный печатный документ и получил картинки четырех страниц:
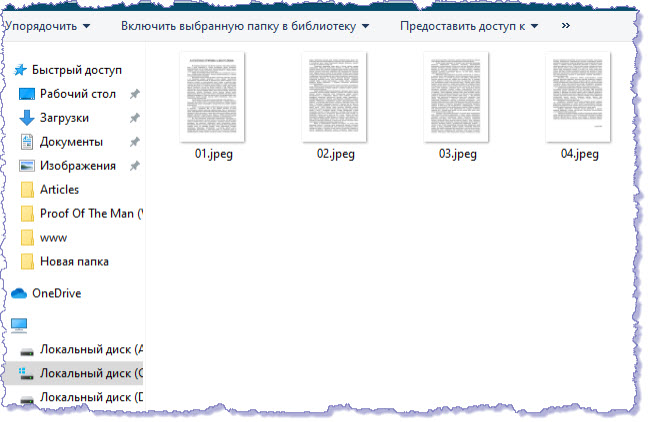
Теперь перейдем на веб-страницу сервиса images.google.com, нажмем кнопку "Поиск по картинке" и загрузим файл с компьютера:
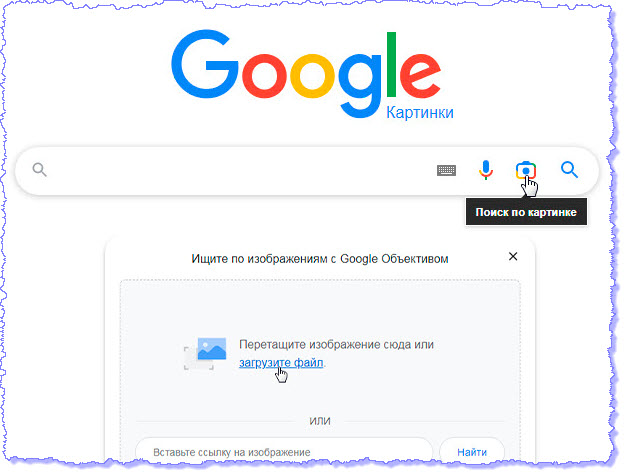
Загружаем сначала скан первой страницы. Нажимаем кнопку "Текст" и затем кнопку "Выбрать весь текст":
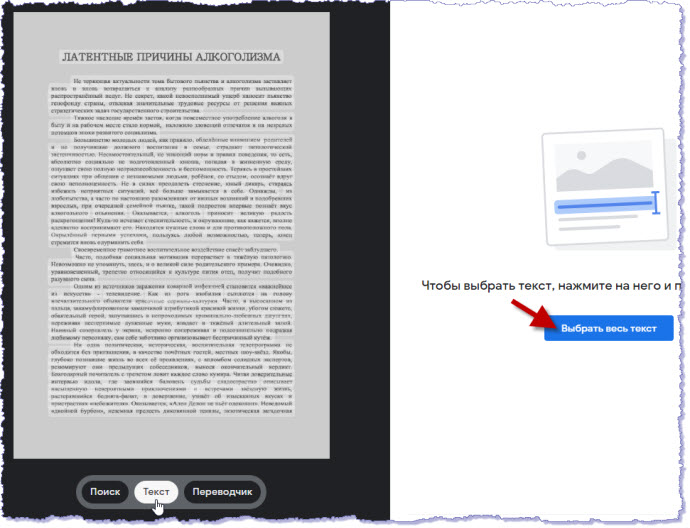
Справа открывается весь текст страницы. Нажимаем кнопку "Копировать текст":
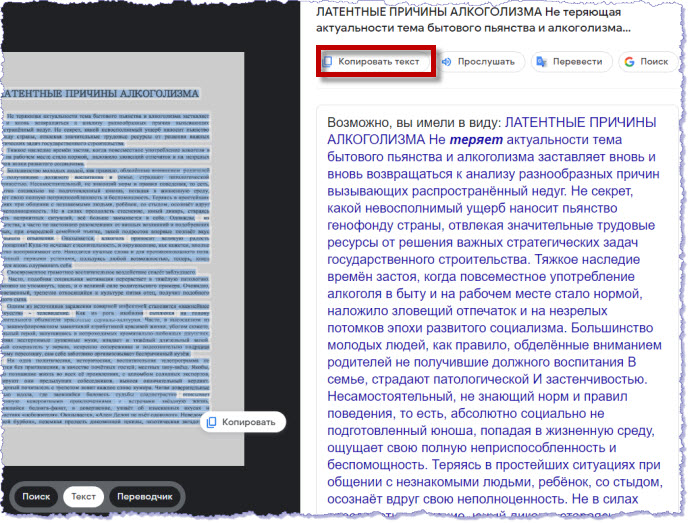
Текст копируется в буфер обмена. После этого открываем редактор MS Word, создаем в нем новый документ и вставляем в него (Ctrl+V) скопированный текст.
О полезных клавиатурных сочетаниях читаем урок: навыки эникейщика
Затем перезагружаем веб-страницу. Для этого нажимаем кнопку "Google":
Открывается главная гуглевская страница https://www.google.com. На ней также нажимаем на значок камеры и далее загружаем в
сервис скан второй страницы нашего документа:
Также выделяем и копируем распознанный текст второй страницы и вставляем его в ворд. То есть добавляем текст в вордовский документ.
Когда все страницы добавлены, редактируем документ, сохраняем его в формате PDF, например, и отправляем на печать. Используя сканер и бесплатный сервис OСR легко извлекаем тексты из картинок.
Так, создав электронную версию печатного текстового документа, распознаем символы текста в ней и правим содержание.
